Differential Privacy
Randomized Response Surveys
Before the age of big data and data science, traditional data collection faced the challenge called the evasive answer bias. That is to say, people not answering survey questions honestly in fear that their answers may be used against them. Randomized responses emerged in the mid-twentieth century to address this.
Randomized response is a technique to protect the privacy of individuals in surveys. It involves adding local noise, such as flipping a coin multiple times and assigning the responses of the individual based on the coin-flip sequence. In doing so, the responses can be true in expectation but any given response is uncertain. This uncertainty over the response of an individual is one of the first applications of differential privacy, although it was not called as such at the time and the quantification of privacy was simply the weighting of probabilities determined by the mechanism.
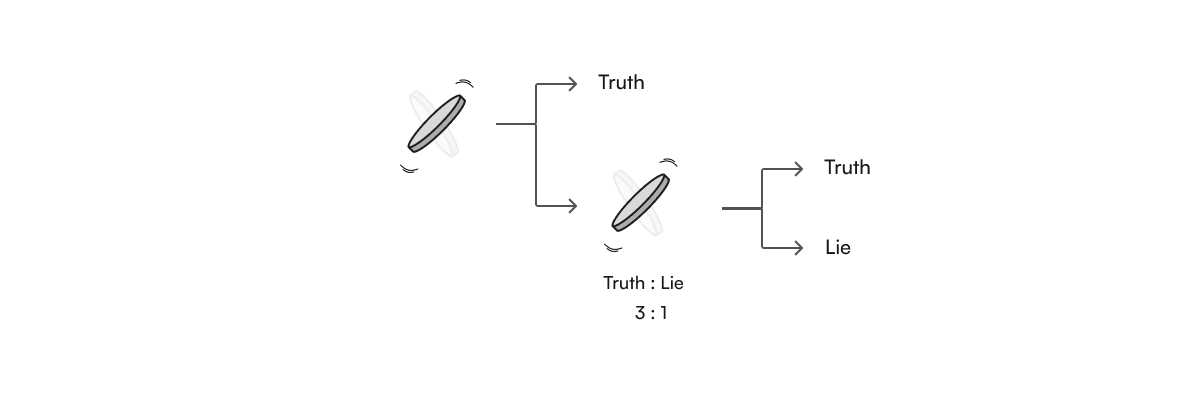
This approach of randomizing the output of the answer to a question by a mechanism, a stochastic intervention such as coin flipping, is still the very backbone of differential privacy today.
(The original approach by S.L. Warner actually involved spinning a “spinner” and as such he could easily change the weighting of the outcome based on the proportion of the circle assigned to each outcome. Whether you prefer a mental model of a roulette wheel, a spinner, coins flipping or dice rolling, as long as we can portray a well calibrated stochastic mechanism which is biased towards the truth, then the approach will work.)
Flavors of Differential Privacy
Since the original development of DP, several other variants of the definition have been developed that maintain its most important properties while offering some additional benefits.
In contrast to the original DP definition, the variants described below can be satisfied using Gaussian noise (which has several important benefits) and also offer tighter composition bounds in many cases. The variants are commonly used in real-world deployments because these advantages can be significant for large releases.
All of the variants described below are relaxations of pure DP, meaning that their guarantees are no stronger than pure DP. In some cases, their guarantees can be weaker. In rare cases, they’re significantly weaker.
The table below summarizes the most commonly used variants of DP. Each has a different set of privacy parameters that describe the strength of the guarantee. These parameters are described below.
| Flavor | Privacy Parameter(s) |
|---|---|
| Pure DP | ϵ |
| Approximate DP | ϵ, δ |
| Zero-concentrated DP | ρ |
| Rényi DP | α, ϵ |
| Gaussian DP | μ |
Why does it matter? Variants of DP other than pure DP provide weaker formal guarantees, but are commonly used due to their significant benefits in privacy analysis and utility. Comparing and interpreting the privacy parameters of different variants is nontrivial and requires careful consideration.
Pure DP
Pure DP has a single privacy parameter (ϵ). A smaller value for ϵ indicates better privacy. The formal definition says that for all neighboring databases \(D_1\) and \(D_2\) and subsets of outputs \(S\), a mechanism \(M\) satisfies \(\epsilon\)-DP if:
\[\frac{\Pr[M(D_1) \in S]}{\Pr[M(D_2) \in S]} \leq e^{\epsilon}\]Randomized Response was ϵ-Differential Privacy
Although randomized response surveys predate the formal definition of differential privacy by over 40 years, the technique directly maps to the binary mechanism used in modern differential privacy.
Assume you wish to set up the spinner originally proposed by Warner to achieve ϵ-differential privacy. This can be done by asking participants to tell the truth with probability \(\frac{e^{\frac{\epsilon}{2}}}{1 + e^{\frac{\epsilon}{2}}}\). This is known in the literature as the binary mechanism.
This mechanism is incredibly useful for building intuition among a non-technical audience. One of the simplest questions we can ask is: “Is Alice in this dataset?” Depending on the level of privacy, the probability of answering truthfully will vary. We illustrate this relationship below.
| ϵ | Probability of Truth | Odds of Truth |
|---|
While the above odds are merely illustrative, they help convey the practical meaning of epsilon in relation to the more intuitive randomized response mechanism. As a point of reference, theorists often advocate for \(\epsilon \approx 1\) for differential privacy guarantees to have a meaningful privacy assurance.
Intuition of the Laplace Mechanism
One of the most widely used mechanisms in ϵ-differential privacy is the Laplace mechanism. It is used when we are adding bounded values together such as counts or summations of private values, provided the extreme values (usually referenced as bounds) of the private values are known and hence the maximum contribution of any data subject is bounded.
In practice, the true sum is first computed, then noise is sampled from the Laplace distribution, and finally this noise is added to the result. For example, if you’re counting and all the values lie within range in (0, 1), the widget below shows how the distribution of noise and expected error change as ϵ varies.
Note that the error is additive and so we can make claims about the absolute error, but not the relative error of the final stochastic result.
Approximate DP
Approximate DP has two privacy parameters (ϵ and δ). As in pure DP, a smaller value for ϵ indicates better privacy. The second parameter, δ, is an additive relaxation parameter. It is often interpreted as a “failure probability” - with probability δ, the privacy guarantee may fail. This interpretation provides useful intuition, though it is not precisely correct. The δ parameter should be set very small - typical values are around \(10^{-5}\) or smaller, and the rule of thumb is to set \(\delta \leq \frac{1}{n^2}\) where \(n\) is the size of the database. The formal definition says that for all neighboring databases \(D_1\) and \(D_2\) and subsets of outputs \(S\), a mechanism \(M\) satisfies \((\epsilon, \delta)\)-DP if:
\[\Pr[M(D_1) \in S] \leq e^\epsilon \Pr[M(D_2) \in S] + \delta\]The following widget describes the expected error for noise added under (ϵ, δ)-DP.
Zero-concentrated DP
Zero-concentrated DP (zCDP) has a single privacy parameter (ρ). A smaller value for ρ indicates better privacy. Typical values for ρ are quite different from typical values of ϵ, and they cannot be directly compared. A zCDP guarantee can be “converted” into an approximate DP guarantee, which can allow for comparisons between parameters, but this conversion may be imprecise. The formal definition says that for all neighboring databases \(D_1\) and \(D_2\) and subsets of outputs \(S\), a mechanism \(M\) satisfies \(\rho\)-zCDP if:
\[\forall \alpha \geq 1. D_\alpha(M(D_1) || M(D_2)) \leq \alpha \rho\]where \(D_\alpha\) is the Rényi divergence of order \(\alpha\).
Rényi DP
Rényi DP (RDP) has two privacy parameters (α and ϵ). As in other definitions, a smaller value for ϵ indicates better privacy, though RDP ϵ values cannot be directly compared with ϵ values from other variants without considering the value of α. The α parameter is an integer greater than 1, and larger values of α indicate better privacy.
Like zCDP, a RDP guarantee can be “converted” into an approximate DP guarantee, but the conversion may be imprecise. The formal definition says that for all neighboring databases \(D_1\) and \(D_2\) and subsets of outputs \(S\), a mechanism \(M\) satisfies \((\alpha, \epsilon)\)-RDP if:
\[D_\alpha(M(D_1) || M(D_2)) \leq \epsilon\]where \(D_\alpha\) is the Rényi divergence of order \(\alpha\).